This was supposed to be a nerdy Christmas present for my students, who, when preparing a thesis on research questions related to the Chinese Internet either find too little or too much existing research. I don’t know if those who “can’t find anything” simply want me to hand them a reading list or did their research when holidaying in North Korea, but be it as it may, they have me trapped. As as a conscientious researcher, I cannot simply say “you are wrong”, but have to provide proof. In doing so, they inadvertently get what they wanted.
As for the others, well, I can relate. Ever so often do I discover linkages between research topics that I did not know existed. So I decided to try and visualise citations centered on work on everything related to the Internet, social media, and all things e- and cyber- and digital. “Centered on” means that there is non-Internet related research that cites or is cited by this literature, and there is Internet-related research on other countries or of a theoretical nature, and I decided that this should be analysed as well.
Doing that, you get a representation of scholarship that so far, colleagues have found useful. Also, by examining how articles cluster, sub- and related research fields can be usefully differentiated. The usual warning: be aware that what you are looking at is a static image of relationships. Research fields change as new articles try hard to challenge established theories, and if such work is really young, you won’t find it in this map. Which means that, sorry to say, dear students, there is still a lot of work to do. I am giving you the haystack, and you now need to find the needle(s).
Graph-tool, Hierarchical Block partition: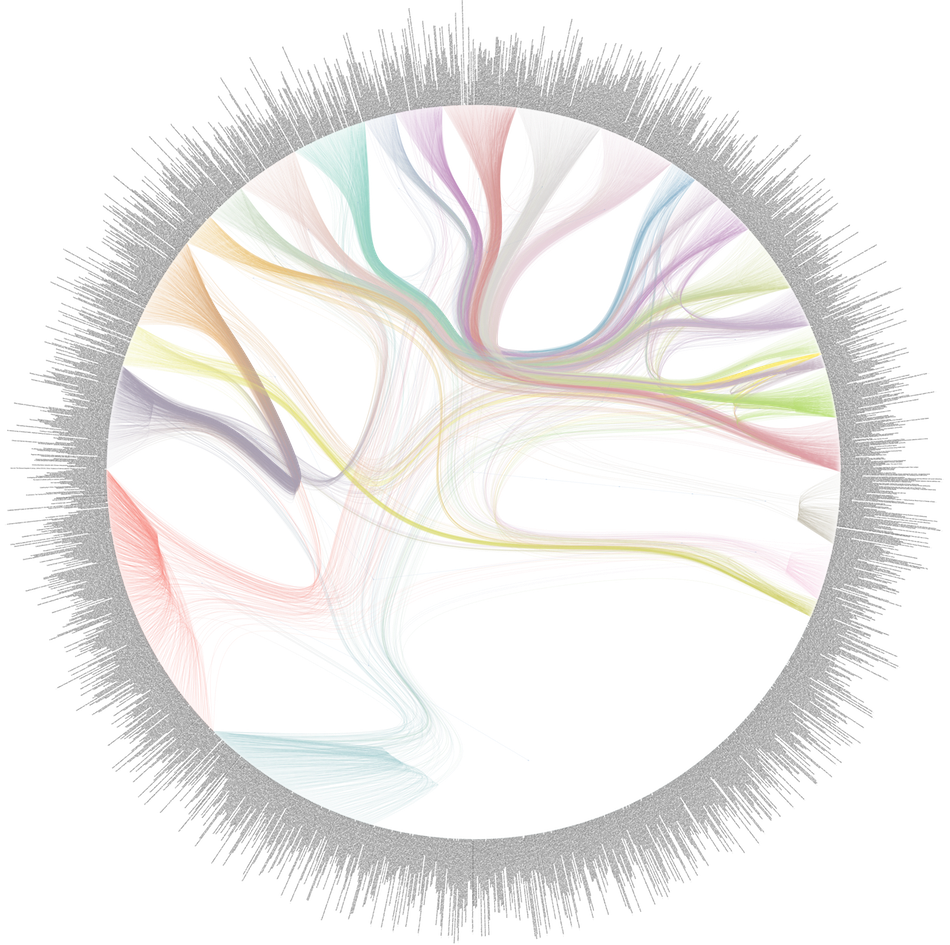
Click here to download high-resolution version (76.6 MB)
Some words regarding methodology. The network is based on data obtained from a search engine where queries return works of interest and books/articles that cited such works. This means that newer research will be underrepresented, but I hope to add some data from another search engine that does the opposite: listing the sources the work in question is based on. A first round of queries yielded titles of about 2.000 documents. In the second round, titles citing those documents were added to the database. These two rounds yielded around 130.000 publication pairs. The fact that A LOT of publications on Chinese politics and economy, but also other theoretical contributions and research on other countries are represented in these pairs testifies to the fact that research on China’s Internet integrates, and is integrated by, other research fields. Here, I restrict the sample to contain only Internet-relevant research. The relationships are mapped using the great, great Graph-tool and python igraph modules.
The most important lesson I learned from this exercise is that visualising that many relations is really, really hard. The graph above is almost too detailed to be immediately useful, and I have literally spent hours investigating the clusters. I also tried other ways of “hierarchisizing” information, for example by letting font sized indicate the number of citations or the “betweenness centrality” score, having an algorithm extract topics from the article abstracts and render different research fields in different colours, and so on.
python-igraph, Fruchterman-Reingold force-directed algorithm
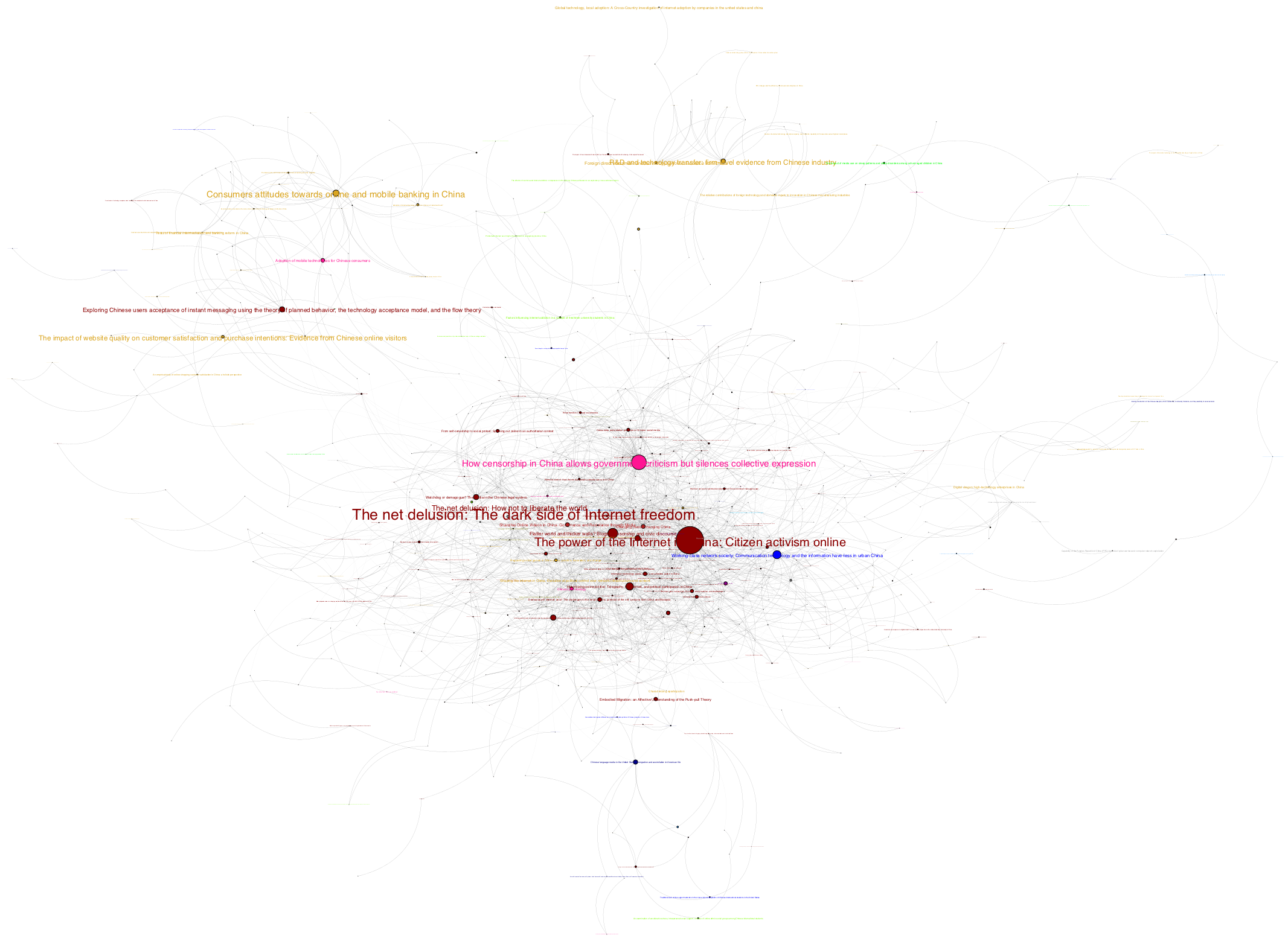
(font size determined by the number of citations, color by subfield)
python igraph, Distributed Recursive Layout algorithm:
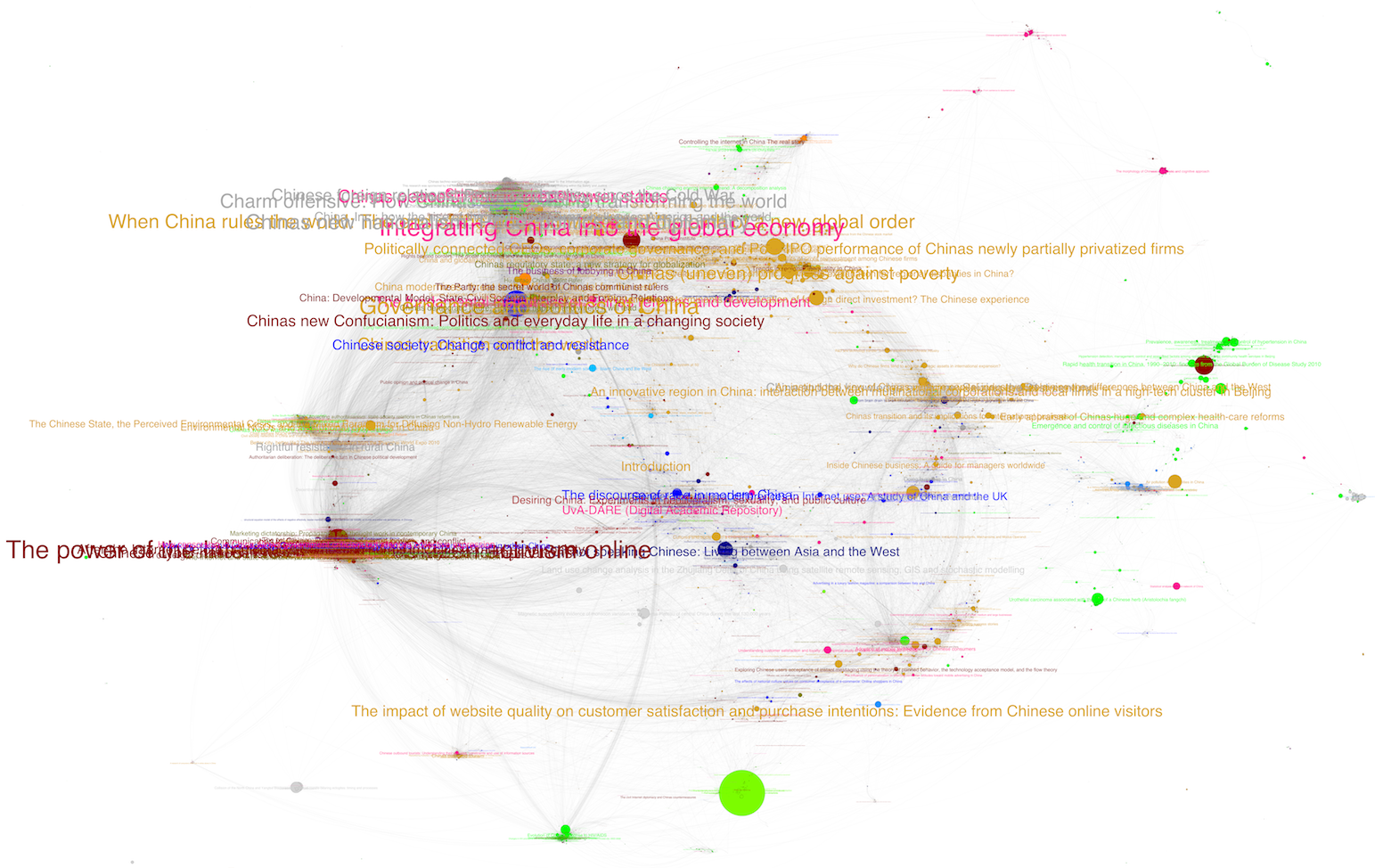
Betweenness centrality, subfields in different colours and too much information.
Click here to download high-resolution version (61.1 MB)
Graph-tool, Price Network:
Betweenness centrality and attempt to spread things out a bit. Also, removed titles not related to China.
Click here to download high-resolution version (20.1 MB)
Please do indicate if you are interested in more information on how I created the map and the science behind measuring influence in networks (lots of literature on the latter!). I know that the question of how to obtain the data will come, so I’ll answer it right here. You either need to download entries by hand (Amazon turk or an “applied research course” would be an option), or automate the process and risk, after the uphill battle of trying to outsmart a tech giant, to eventually get banned for violating a search engine’s terms of service. Getting the data, which is only one click away, is unfortunately the greatest challenge.